Levenshtein distance in MySQL and fuzzy search algorithms using PHP
The famous Soviet and Russian mathematician Vladimir Iosifovich Levenshtein (by the way, who died a little over two months ago) at the beginning of the second half of the last century introduced the concept of editing distance , which we use to this day in various fields - from search engines to bioinformatics. In this article, we will apply its principle for fuzzy searching in MySQL (since MySQL currently does not offer an embedded solution), calculating the most efficient (i.e. fast) method from several found on the Internet, build an algorithm for such a search and implement it on PHP
What will we use:
Obviously, with each search, it makes no sense to calculate the Levenshtein distance between the entered word and each word from the dictionary in the database, since it will take a lot of time. By the way, several years ago, a method was described in Habré where, with each search, the entire dictionary from the database was pushed into a PHP array, transliterated, and similar words were selected further, alternately using either the levenshtein function, the metaphone, the similar_text, or two at once. The solution of preliminary rapid filtering and subsequent refining of the options found suggests itself.
Thus, the essence of the fuzzy search algorithm can be summarized as follows:
With each search, it will be necessary to calculate the Levenshtein distance. To do this, you need to find the fastest implementation of the algorithm for MySQL.
For all tests, a base of settlements was selected, 4 years ago pulled out of Vkontakte. For the tests, a table of cities was used, which contains more than 2.2 million records, partially translated into 13 languages. Only columns with Russian translations were left, which contained many untranslated titles. Also an index was made for the city_id column.
The next step was the formation of a metaphone for each title. Since the metaphone is calculated only from strings containing letters of the English alphabet, each name must first be converted: transliterate Cyrillic letters, and Latin letters containing accents must be converted into letters of the English alphabet.
Thus, the PHP code for adding a metaphone column is as follows:
For 2,246,813 lines, the calculation of the metaphone and its insertion took ~ 38 minutes.
Also an index was made on the metaphone column, since further search operations will take place only in it.
As noted earlier, three implementations will be checked for speed — the Flattery query, the Rast function, and the Torres function.
For the tests, 5 words will be used (or rather, their erroneous spelling), 3 of them are in Cyrillic, and 2 in Latin:
In the last word, more mistakes were intentionally made so that the Levenshtein distance was 2 characters. If each method works correctly, when searching for the last word, 0 lines will be returned each time.
The first option is the most primitive of all three: here the principle of Levenshtein distance (insert, delete and replace), which is simulated in a SQL query using a large number of LIKE operators, is taken as a basis. If the string (word) consists of characters (letters), the number of LIKE operators when searching for Levenshtein distance of 1 character will be equal to (or when searching for Levenshtein distance <2 characters).
At the end of the article, the author offers a PHP function to automate the compilation of such SQL queries. This function has been changed for our search by metaphones, but the principle is the same:
LIKE was checked with both search patterns , both with an underscore and with a percent sign.
The longer the word, the more time is needed to search for similar metaphones (which is obvious), but, at the same time, the longer the word, the less time is spent on each letter (which is not obvious). Let's pretend that - the total time spent searching for similar metaphones, and - the total number of letters in the metaphone for which we were looking for similarities; if the first word is shorter than the second ( ) and, accordingly, the total time spent searching for similar metaphones for the first word is less than for the second ( ), then
The second option is the user-defined levenshtein function, which takes two parameters — two VARCHAR strings (255), and returns the INT number — the Levenshtein distance. The auxiliary function levenshtein_ratio is also proposed, which, on the basis of the Levenshtein distance calculated by the previous function, returns the percent similarity of two lines (by analogy with the PHP function similar_text). We will test only the first function.
Let's try to find all the words with a Levenshtein distance of 1 character:
The search for similar metaphones for the fourth title (which has the shortest metaphone) gave the same results as when searching with LIKE with the search pattern "_", but took ~ 66 minutes, so it was decided not to continue testing the other words.
The third option is the implementation of a function written in C by Linus Torvalds . This function takes three parameters — two strings for comparison, and the integer INT — the upper bound, i.e. the maximum number of characters that will be taken from each line for comparison.
Set a universal upper limit for all metaphones from our test - 20 characters, and try to find all the words with a Damerau-Levenshtein distance of 1 character:
Results:
The Torres function showed excellent results in comparison with the Flattery query, and especially in comparison with the Rast function. The second plus is that Torres used the advanced Damerau-Levenshtein algorithm, where a transposition operation was added to the insert, delete, and replace operations. Compare the results of the Torres function and the Flattery query:
The difference in the number of rows returned can be explained by the difference in the algorithms used (Levenshtein and Damerau-Levenshtein for the Flattery query and the Torres function, respectively). In 5 cases out of 5 the winner was the Torres function, so it will be used in the final implementation in PHP, where the result is refined by the function similar_text.
The most accurate refining results can be obtained if the search query is not transliterated, i.e. after receiving similar words they will be compared with the original. During the experiments, it was found that the function similar_text returns different results for words in Cyrillic and Latin at the same Levenshtein distance. Therefore, for the purity of calculations, the utf8_to_extended_ascii function , originally proposed by luciole75w , will be additionally used to solve the same problem when using the PHP levenshtein function.
The result might look like this:
The implementation of the Damerau-Levenshtein distance, written by Linus Torvalds in C and adapted by Diego Torres for MySQL as a user function, turned out to be the fastest. In second place with a small time difference, there is a primitive imitation of Levenshtein distance in the form of a SQL query with a large number of LIKE operators, the author is Gordon Flattery. In third place, the user function for MySQL from Jason Rast was far behind.
In conclusion, I would like to add that using Levenshtein distance calculation in MySQL in production is necessary only in cases where the line to compare is short, and the table with the words to be compared with the line is small. Otherwise, a possible solution in the case of a table with a large dictionary may be its division into several tables, for example, by the first letter, or by the length of a word or its metaphone.
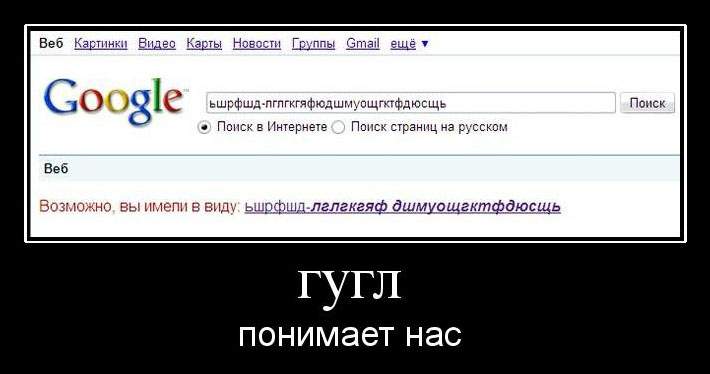
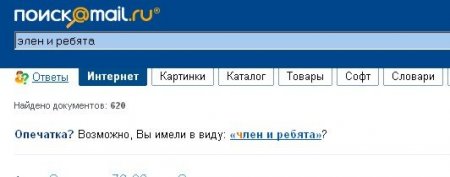
Most often, the field of application of fuzzy search algorithms in the web is searching for names and names using an existing dictionary, where there is a high probability that a user can make a typo or make a mistake of at least 1 character. In any case, try to ensure that the options offered by your script do not become the object of screenshots:
PS Another article with other MySQL user functions for calculating the Levenshtein distance.
PPS In the comments YourChief suggests that for production it is much more efficient to use the Levenshtein machine gun .
What will we use:
- Levenshtein distance and Damerau-Levenshtein distance : both represent the minimum number of operations for converting one string to another, differing in operations - Levenshtein suggested inserting , deleting and replacing one character, and Damerau added them with a transposition operation, i.e. when two adjacent symbols change places; The following implementations have been proposed for MySQL:
- request in the style of the Levenshtein algorithm , by Gordon Lesti
- user function for calculating the Levenshtein distance, published in the book Get It Done With MySQL 5 & Up (ed. Peter Brawley and Arthur Fuller), by Just Rust
- custom function for calculating the Damerau-Levenshtein distance, written on the basis of a C function written by Linus Torvalds, by Diego Torres
- Oliver's algorithm : calculates the similarity of two lines
- in PHP is represented by the function similar_text
- metaphone : the algorithm for indexing words according to the phonetic principle, works only with letters of the English alphabet
- in PHP is represented by the metaphone function
What we will not use
- soundex and its PHP function
- all the remaining algorithms , since PHP has no corresponding functions.
Fuzzy search algorithm
Obviously, with each search, it makes no sense to calculate the Levenshtein distance between the entered word and each word from the dictionary in the database, since it will take a lot of time. By the way, several years ago, a method was described in Habré where, with each search, the entire dictionary from the database was pushed into a PHP array, transliterated, and similar words were selected further, alternately using either the levenshtein function, the metaphone, the similar_text, or two at once. The solution of preliminary rapid filtering and subsequent refining of the options found suggests itself.
Thus, the essence of the fuzzy search algorithm can be summarized as follows:
- Calculate the search query metaphone.
- Find all words in the dictionary in the database by metaphone with Levenshtein distance (or Damerau-Levenshtein) <2 characters.
- If nothing is found - the user has made too many errors in the word, stop tormenting the database and write that the
user goes to the bath andnothing is found. - If 1 word is found, return it.
- If found> 1 words - refined: find the percentage of similarity of the search query with each found word from the dictionary in the database; find the maximum percentage of similarity; return all words with this percentage (in case several words have the same percentage, which will be the maximum).
With each search, it will be necessary to calculate the Levenshtein distance. To do this, you need to find the fastest implementation of the algorithm for MySQL.
DB Preparation
For all tests, a base of settlements was selected, 4 years ago pulled out of Vkontakte. For the tests, a table of cities was used, which contains more than 2.2 million records, partially translated into 13 languages. Only columns with Russian translations were left, which contained many untranslated titles. Also an index was made for the city_id column.
The next step was the formation of a metaphone for each title. Since the metaphone is calculated only from strings containing letters of the English alphabet, each name must first be converted: transliterate Cyrillic letters, and Latin letters containing accents must be converted into letters of the English alphabet.
Thus, the PHP code for adding a metaphone column is as follows:
// set_time_limit(0); ini_set('max_execution_time', 0); // , $from = ['', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', 'á', 'ă', 'ắ', 'ặ', 'ằ', 'ẳ', 'ẵ', 'ǎ', 'â', 'ấ', 'ậ', 'ầ', 'ẩ', 'ẫ', 'ä', 'ǟ', 'ȧ', 'ǡ', 'ạ', 'ȁ', 'à', 'ả', 'ȃ', 'ā', 'ą', 'ᶏ', 'ẚ', 'å', 'ǻ', 'ḁ', 'ⱥ', 'ã', 'ɐ', 'ₐ', 'ḃ', 'ḅ', 'ɓ', 'ḇ', 'ᵬ', 'ᶀ', 'ƀ', 'ƃ', 'ć', 'č', 'ç', 'ḉ', 'ĉ', 'ɕ', 'ċ', 'ƈ', 'ȼ', 'ↄ', 'ꜿ', 'ď', 'ḑ', 'ḓ', 'ȡ', 'ḋ', 'ḍ', 'ɗ', 'ᶑ', 'ḏ', 'ᵭ', 'ᶁ', 'đ', 'ɖ', 'ƌ', 'ꝺ', 'é', 'ĕ', 'ě', 'ȩ', 'ḝ', 'ê', 'ế', 'ệ', 'ề', 'ể', 'ễ', 'ḙ', 'ë', 'ė', 'ẹ', 'ȅ', 'è', 'ẻ', 'ȇ', 'ē', 'ḗ', 'ḕ', 'ⱸ', 'ę', 'ᶒ', 'ɇ', 'ẽ', 'ḛ', 'ɛ', 'ᶓ', 'ɘ', 'ǝ', 'ₑ', 'ḟ', 'ƒ', 'ᵮ', 'ᶂ', 'ꝼ', 'ǵ', 'ğ', 'ǧ', 'ģ', 'ĝ', 'ġ', 'ɠ', 'ḡ', 'ᶃ', 'ǥ', 'ᵹ', 'ɡ', 'ᵷ', 'ḫ', 'ȟ', 'ḩ', 'ĥ', 'ⱨ', 'ḧ', 'ḣ', 'ḥ', 'ɦ', 'ẖ', 'ħ', 'ɥ', 'ʮ', 'ʯ', 'í', 'ĭ', 'ǐ', 'î', 'ï', 'ḯ', 'ị', 'ȉ', 'ì', 'ỉ', 'ȋ', 'ī', 'į', 'ᶖ', 'ɨ', 'ĩ', 'ḭ', 'ı', 'ᴉ', 'ᵢ', 'ǰ', 'ĵ', 'ʝ', 'ɉ', 'ȷ', 'ɟ', 'ʄ', 'ⱼ', 'ḱ', 'ǩ', 'ķ', 'ⱪ', 'ꝃ', 'ḳ', 'ƙ', 'ḵ', 'ᶄ', 'ꝁ', 'ꝅ', 'ʞ', 'ĺ', 'ƚ', 'ɬ', 'ľ', 'ļ', 'ḽ', 'ȴ', 'ḷ', 'ḹ', 'ⱡ', 'ꝉ', 'ḻ', 'ŀ', 'ɫ', 'ᶅ', 'ɭ', 'ł', 'ꞁ', 'ḿ', 'ṁ', 'ṃ', 'ɱ', 'ᵯ', 'ᶆ', 'ɯ', 'ɰ', 'ń', 'ň', 'ņ', 'ṋ', 'ȵ', 'ṅ', 'ṇ', 'ǹ', 'ɲ', 'ṉ', 'ƞ', 'ᵰ', 'ᶇ', 'ɳ', 'ñ', 'ó', 'ŏ', 'ǒ', 'ô', 'ố', 'ộ', 'ồ', 'ổ', 'ỗ', 'ö', 'ȫ', 'ȯ', 'ȱ', 'ọ', 'ő', 'ȍ', 'ò', 'ỏ', 'ơ', 'ớ', 'ợ', 'ờ', 'ở', 'ỡ', 'ȏ', 'ꝋ', 'ꝍ', 'ⱺ', 'ō', 'ṓ', 'ṑ', 'ǫ', 'ǭ', 'ø', 'ǿ', 'õ', 'ṍ', 'ṏ', 'ȭ', 'ɵ', 'ɔ', 'ᶗ', 'ᴑ', 'ᴓ', 'ₒ', 'ṕ', 'ṗ', 'ꝓ', 'ƥ', 'ᵱ', 'ᶈ', 'ꝕ', 'ᵽ', 'ꝑ', 'ʠ', 'ɋ', 'ꝙ', 'ꝗ', 'ŕ', 'ř', 'ŗ', 'ṙ', 'ṛ', 'ṝ', 'ȑ', 'ɾ', 'ᵳ', 'ȓ', 'ṟ', 'ɼ', 'ᵲ', 'ᶉ', 'ɍ', 'ɽ', 'ꞃ', 'ɿ', 'ɹ', 'ɻ', 'ɺ', 'ⱹ', 'ᵣ', 'ś', 'ṥ', 'š', 'ṧ', 'ş', 'ŝ', 'ș', 'ṡ', 'ṣ', 'ṩ', 'ʂ', 'ᵴ', 'ᶊ', 'ȿ', 'ꞅ', 'ſ', 'ẜ', 'ẛ', 'ẝ', 'ť', 'ţ', 'ṱ', 'ț', 'ȶ', 'ẗ', 'ⱦ', 'ṫ', 'ṭ', 'ƭ', 'ṯ', 'ᵵ', 'ƫ', 'ʈ', 'ŧ', 'ꞇ', 'ʇ', 'ú', 'ŭ', 'ǔ', 'û', 'ṷ', 'ü', 'ǘ', 'ǚ', 'ǜ', 'ǖ', 'ṳ', 'ụ', 'ű', 'ȕ', 'ù', 'ᴝ', 'ủ', 'ư', 'ứ', 'ự', 'ừ', 'ử', 'ữ', 'ȗ', 'ū', 'ṻ', 'ų', 'ᶙ', 'ů', 'ũ', 'ṹ', 'ṵ', 'ᵤ', 'ṿ', 'ⱴ', 'ꝟ', 'ʋ', 'ᶌ', 'ⱱ', 'ṽ', 'ʌ', 'ᵥ', 'ẃ', 'ŵ', 'ẅ', 'ẇ', 'ẉ', 'ẁ', 'ⱳ', 'ẘ', 'ʍ', 'ẍ', 'ẋ', 'ᶍ', 'ₓ', 'ý', 'ŷ', 'ÿ', 'ẏ', 'ỵ', 'ỳ', 'ƴ', 'ỷ', 'ỿ', 'ȳ', 'ẙ', 'ɏ', 'ỹ', 'ʎ', 'ź', 'ž', 'ẑ', 'ʑ', 'ⱬ', 'ż', 'ẓ', 'ȥ', 'ẕ', 'ᵶ', 'ᶎ', 'ʐ', 'ƶ', 'ɀ', 'ß' ]; // , $to = ['a', 'b', 'v', 'g', 'd', 'e', 'yo', 'zh', 'z', 'i', 'y', 'k', 'l', 'm', 'n', 'o', 'p', 'r', 's', 't', 'u', 'f', 'h', 'ts', 'ch', 'sh', 'shch', '', 'y', '', 'e', 'yu', 'ya', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'b', 'b', 'b', 'b', 'b', 'b', 'b', 'b', 'c', 'c', 'c', 'c', 'c', 'c', 'c', 'c', 'c', 'c', 'c', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'f', 'f', 'f', 'f', 'f', 'g', 'g', 'g', 'g', 'g', 'g', 'g', 'g', 'g', 'g', 'g', 'g', 'g', 'h', 'h', 'h', 'h', 'h', 'h', 'h', 'h', 'h', 'h', 'h', 'h', 'h', 'h', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'j', 'j', 'j', 'j', 'j', 'j', 'j', 'j', 'k', 'k', 'k', 'k', 'k', 'k', 'k', 'k', 'k', 'k', 'k', 'k', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'm', 'm', 'm', 'm', 'm', 'm', 'm', 'm', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'p', 'p', 'p', 'p', 'p', 'p', 'p', 'p', 'p', 'q', 'q', 'q', 'q', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 't', 't', 't', 't', 't', 't', 't', 't', 't', 't', 't', 't', 't', 't', 't', 't', 't', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'v', 'v', 'v', 'v', 'v', 'w', 'w', 'w', 'w', 'w', 'w', 'w', 'w', 'w', 'x', 'x', 'x', 'x', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'z', 'z', 'z', 'z', 'z', 'z', 'z', 'z', 'z', 'z', 'z', 'z', 'z', 'z', 'ss']; // function mtphn($s){ // return metaphone( str_replace($from, $to, mb_strtolower($s)) ); } // $conn = mysqli_connect('localhost','root','','test') or die(mysqli_error($conn)); // mysqli_query($conn, "ALTER TABLE _cities ADD COLUMN metaphone VARCHAR(30) DEFAULT NULL"); // id $q = mysqli_query($conn, "SELECT city_id, title_ru FROM _cities"); while ($row = mysqli_fetch_assoc($q)) // mysqli_query($conn, "UPDATE _cities SET metaphone='".mtphn($row['title_ru'])."' WHERE city_id=".$row['city_id']); mysqli_close($conn); // echo '. '.( microtime(true) - $_SERVER["REQUEST_TIME_FLOAT"] ).' .'; For 2,246,813 lines, the calculation of the metaphone and its insertion took ~ 38 minutes.
Also an index was made on the metaphone column, since further search operations will take place only in it.
Selecting Levenshtein distance implementation for MySQL
As noted earlier, three implementations will be checked for speed — the Flattery query, the Rast function, and the Torres function.
For the tests, 5 words will be used (or rather, their erroneous spelling), 3 of them are in Cyrillic, and 2 in Latin:
| No | Correct writing | His metaphone | Wrong spelling | His metaphone | Levenshtein metaphones |
| one. | Aleksandrovsk-Sakhalinsky | ALKSNTRFSKSHLNSK | Al and xander sa vsk-sa g olin z kiy | ALKSNTRFSKS K LNSK | one |
| 2 | Semikarakorsk | SMKRKRSK | Semik about raco in sk | SMKRK F SK | one |
| 3 | Charentsavan | XRNTSFN | H | XRNTS F | one |
| four. | Bounounbougoula | BNNBKL | B o n u nb o g uv a | BNNBK F | one |
| five. | Kampong Tenaki Kawang | KMPNKTNKKWNK | Kampo nt enaki ka ang | KMP NT NKK F NK | 2 |
Flattery Request
The first option is the most primitive of all three: here the principle of Levenshtein distance (insert, delete and replace), which is simulated in a SQL query using a large number of LIKE operators, is taken as a basis. If the string (word) consists of characters (letters), the number of LIKE operators when searching for Levenshtein distance of 1 character will be equal to (or when searching for Levenshtein distance <2 characters).
At the end of the article, the author offers a PHP function to automate the compilation of such SQL queries. This function has been changed for our search by metaphones, but the principle is the same:
// $input = ''; // $input_m = mtphn($input); // , LIKE SQL- // $q_likes = [$input_m . '_']; // for ($i = 0, $len = strlen($input_m); $i < $len; $i++) // , for($n = 1; $n < 4; $n++) $q_likes[] = substr( $input_m, 0, $i ) . ($n & 1 ? '_' : '') . substr( $input_m, $i + ($n > 1 ? 1 : 0) ); // $conn = mysqli_connect('localhost','root','','test') or die(mysqli_error($conn)); // + $q = mysqli_query($conn, "SELECT city_id, title_ru FROM _cities WHERE metaphone LIKE '".implode("' OR metaphone LIKE '",$q_likes)."'"); // mysqli_close($conn); // $result = []; // while($row = mysqli_fetch_assoc($q)) $result[] = [ $row['city_id'], $row['title_ru'] ]; // // echo'<pre>'; print_r($result); echo'</pre>'; echo '<p>. '.( microtime(true) - $_SERVER["REQUEST_TIME_FLOAT"] ).' '; LIKE was checked with both search patterns , both with an underscore and with a percent sign.
| Word number | t for LIKE with "_", sec | Found | t for LIKE with "%", s | Found |
| one. | 24.2 | one | 24.6 | one |
| 2 | 14.1 | one | 14.8 | four |
| 3 | 11.9 | 188 | 12.3 | 224 |
| four. | 11.9 | 70 | 12.8 | 87 |
| five. | 18.1 | 0 | 19.6 | 0 |
A sharp increase in time was also expected when replacing the search pattern "_" with "%", but the total time increased from 2-8%.
Rasta function
The second option is the user-defined levenshtein function, which takes two parameters — two VARCHAR strings (255), and returns the INT number — the Levenshtein distance. The auxiliary function levenshtein_ratio is also proposed, which, on the basis of the Levenshtein distance calculated by the previous function, returns the percent similarity of two lines (by analogy with the PHP function similar_text). We will test only the first function.
Let's try to find all the words with a Levenshtein distance of 1 character:
SELECT city_id, title_ru FROM _cities WHERE levenshtein("BNNBKF",metaphone)=1 The search for similar metaphones for the fourth title (which has the shortest metaphone) gave the same results as when searching with LIKE with the search pattern "_", but took ~ 66 minutes, so it was decided not to continue testing the other words.
Torres function
The third option is the implementation of a function written in C by Linus Torvalds . This function takes three parameters — two strings for comparison, and the integer INT — the upper bound, i.e. the maximum number of characters that will be taken from each line for comparison.
Set a universal upper limit for all metaphones from our test - 20 characters, and try to find all the words with a Damerau-Levenshtein distance of 1 character:
SELECT city_id, title_ru FROM _cities WHERE damlevlim("BNNBKF",metaphone,20)=1 Results:
| Word number | t for Torres f-ii, s | Found |
| one. | 11.24 | one |
| 2 | 9.25 | one |
| 3 | 9.19 | 173 |
| four. | 8.3 | 86 |
| five. | 11.57 | 0 |
| Word number | t for request Flattery, sec | t for Torres f-ii, s | Request Flattery, found words | F. Torres, found words |
| one. | 24.2 | 11.24 | one | one |
| 2 | 14.1 | 9.25 | one | one |
| 3 | 11.9 | 9.19 | 188 | 173 |
| four. | 11.9 | 8.3 | 70 | 86 |
| five. | 18.1 | 11.57 | 0 | 0 |
PHP implementation
The most accurate refining results can be obtained if the search query is not transliterated, i.e. after receiving similar words they will be compared with the original. During the experiments, it was found that the function similar_text returns different results for words in Cyrillic and Latin at the same Levenshtein distance. Therefore, for the purity of calculations, the utf8_to_extended_ascii function , originally proposed by luciole75w , will be additionally used to solve the same problem when using the PHP levenshtein function.
// $input = ''; // similar_text UTF-8 function utf8_to_extended_ascii($str, &$map){ $matches = array(); if (!preg_match_all('/[\xC0-\xF7][\x80-\xBF]+/', $str, $matches)) return $str; foreach ($matches[0] as $mbc) if (!isset($map[$mbc])) $map[$mbc] = chr(128 + count($map)); return strtr($str, $map); } // function damlev($input){ // $input_m = mtphn($input); // $conn = mysqli_connect('localhost','root','','test') or die(mysqli_error($conn)); // - 0 1 $q = mysqli_query($conn, 'SELECT city_id, title_ru FROM _cities WHERE damlevlim("'.$input_m.'",metaphone,20)<2'); // mysqli_close($conn); // while ($row = mysqli_fetch_assoc($q)) $damlev_result[] = [ $row['city_id'], $row['title_ru'] ]; // 1 - if (count($damlev_result) > 1){ // foreach ($damlev_result as $v) // // similar_text( utf8_to_extended_ascii($input,$charMap), utf8_to_extended_ascii($v[1],$charMap), $similar_text_result[] ); // $max_similarity = max($similar_text_result); // $most_similar_strings = array_flip( array_keys($similar_text_result, $max_similarity) ); // return array_intersect_key($damlev_result,$most_similar_strings); } // 1 - // 1 else return $damlev_result; } echo '<p> : '.$input; $output = damlev($input); // if (count($output) > 0){ // - foreach ($output as $v) // $results_list[] = '<a href="search.php?id='.$v[0].'">' .$v[1].'</a>'; echo '<p>, : '.implode(', ',$results_list); } else // - , echo'<p> , .'; The result might look like this:
| We are looking for name: Cherentseva Perhaps you are looking for: Charentsavan , Cherentsovka |
Results
The implementation of the Damerau-Levenshtein distance, written by Linus Torvalds in C and adapted by Diego Torres for MySQL as a user function, turned out to be the fastest. In second place with a small time difference, there is a primitive imitation of Levenshtein distance in the form of a SQL query with a large number of LIKE operators, the author is Gordon Flattery. In third place, the user function for MySQL from Jason Rast was far behind.
In conclusion, I would like to add that using Levenshtein distance calculation in MySQL in production is necessary only in cases where the line to compare is short, and the table with the words to be compared with the line is small. Otherwise, a possible solution in the case of a table with a large dictionary may be its division into several tables, for example, by the first letter, or by the length of a word or its metaphone.
Most often, the field of application of fuzzy search algorithms in the web is searching for names and names using an existing dictionary, where there is a high probability that a user can make a typo or make a mistake of at least 1 character. In any case, try to ensure that the options offered by your script do not become the object of screenshots:
PS Another article with other MySQL user functions for calculating the Levenshtein distance.
PPS In the comments YourChief suggests that for production it is much more efficient to use the Levenshtein machine gun .
More posts:
All Posts